In Microsoft Fabric data engineering, we use Spark to apply transformations to our data. Just like you would write T-SQL to transform data in SQL Server, you would write PySpark or SparkSQL to transform data in a Fabric lakehouse.
There are a lot of parallels between Spark en SQL in the way you can process data. However, there are also some fundamental differences! Today, we’re going to look at how Spark dataframes work differently than one might think when just starting out.
What is a Spark Dataframe?
A Spark dataframe is, according to the Apache Spark documentation, “A distributed collection of data grouped into named columns”. In other words, it’s a kind of table structure that you can do data operations with. The Spark documentation mentions that a dataframe is equivalent to a relational table in a database, however, there are some differences. This article will describe some of those differences.
How We Use Spark Dataframes in Microsoft Fabric
In Microsoft Fabric Spark, we can use dataframes in Spark within Notebooks, for example as intermediate data structures on which we can do data transformations (for example, between Silver and Gold in the medallion architecture).
In the past, we would have done the same thing in a database. In that case, the Notebook object in Fabric is functionally equivalent to a Stored Procedure in SQL. In those stored procedures, I would regularly use temporary tables (#table) to store intermediate data used in the further processing of a transformation.
In Spark notebooks, you can achieve the same thing using dataframes instead of temporary tables. The only downside is: a dataframe is not a table but a view…
Spark Dataframe is a View, Not a Table
I was building a mechanism to implement time travel into a delta table in my lakehouse. In order to do so, I was reading data from a delta table into a dataframe, reading new data into a dataframe, determining differences, and then merge those differences into the delta table.
In doing so, I encountered some unexpected results. After further investigation, it seemed that the first dataframe I created was updated after updating the underlying delta table. And that’s strange, because with SQL still fresh in my mind (I’m a very traditionally SQL-oriented engineer…) I assumed that a dataframe would behave as a temporary table. Assumptions start with ‘ass’ for a reason…
In the end I found a solution, and I decided to write this blog post to help out others that might run into the same issue as me.
Notebook Showing Dataframe is a View
I created a very simple notebook in which I can showcase the issue. I could reproduce the issue by following along with these steps.
from pyspark.sql import SparkSession
from delta.tables import DeltaTable
from pyspark.sql.types import StructType, StructField, LongType, BooleanType
from pyspark.sql import Row
from pyspark.sql import functions as FThat works just fine. Nothing much to do here.
## create Delta table in lakehouse
spark.sql("drop table if exists default.aaa_test_table")
schema = StructType([
StructField('id', LongType(), True),
StructField('value', LongType(), True),
StructField('active', BooleanType(), True),
])
df = spark.createDataFrame([[1,5,True], [2,6,True], [3, 5, True]], schema)
table_path = "Tables/aaa_test_table"
df.write.format('delta').mode('overwrite').save(table_path)
## read Delta table back to Spark DataFrame, should display 3 rows (and does so)
df = spark.read.format('delta').load('Tables/aaa_test_table')
display(df) 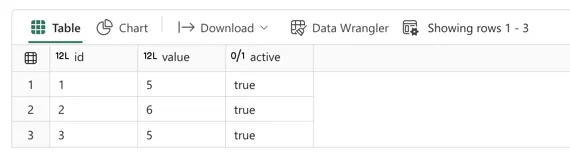
This one also works just as expected. I declared a new dataframe containing three rows manually created in the spark.createDataFrame() method above.
## filter DataFrame on column 'active' being True, should display 3 rows (and does so)
test_df = df.filter(F.col('active') == True)
display(test_df)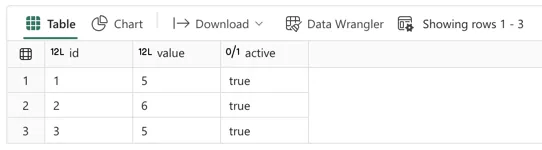
In this next step I created a new dataframe called test_df and filled it with a filtered result set of the original df. In this case, I filtered for active = True which results in all three rows being returned.
## Update specific row in Delta table, set one value for column 'active' to False
delta_table = DeltaTable.forPath(spark,'Tables/aaa_test_table')
df_u = spark.createDataFrame([[2,6,False]], schema)
delta_table.alias('t').merge(
source=df_u.alias('s'),
condition="`t`.`id` = `s`.`id`"
).whenMatchedUpdateAll().execute()
## display the changed Delta table
display(spark.read.format('delta').load('Tables/aaa_test_table'))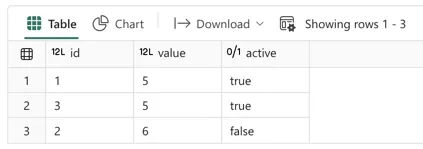
Then, I create a dataframe to update the original delta table. I called this dataframe df_u and I inserted 1 row of data. Then, I merged this dataframe into the delta table using the dataframe as the source (s) and delta table as target (t). Since I ran the update using the id column as the key, this performed an update of the row with id = 2 (active was set to False). As you can see in the result below the code, that was indeed the case.
## display test_df again without having changed it
## it should display 3 rows but instead only shows the 2 active rows
display(test_df)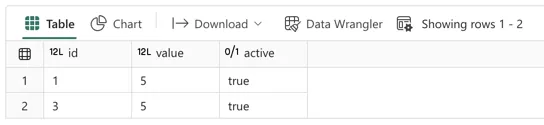
The unexpected (at least by me) behaviour here is that the dataframe now only shows 2 rows instead of 3. Since the dataframe was created using a filter on active = True, and we updated one of the rows to be False, that row is omitted in the current dataframe.
Depending on your use case, this behaviour can be intended or not. Below, I will showcase how to change this behaviour using one simple little trick.
## filter DataFrame on column 'active' being True, should display 3 rows (and does so)
test_df = df.filter(F.col('active') == True)
test_df = test_df.collect()
display(test_df)This cell has an extra line: test_df = test_df.collect(). The collect method on a Spark dataframe is interesting. It returns all the records of a dataframe as a list of Rows. That means that you will get a new dataframe, overwrite the variable currently holding the dataframe, with hardcoded data of the old dataframe. Makes sense, right? It does when we watch the code below.
Let’s assume the update of the delta table works exactly the same as before. The table now contains three rows, of which two rows have active = True and one row has active = False. We can now display the test_df again:
## display test_df again without having changed it
## it should display 3 rows but instead only shows the 2 active rows
display(test_df)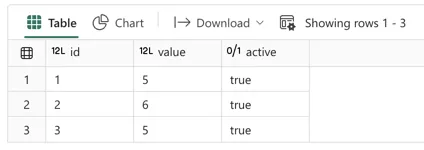
As you can see, the original three rows were preserved in the test_df this time. All because collect() looked for the actual content of the dataframe, and wrote the list of rows back to this dataframe, it is now decoupled from the underlying delta table.
If you want to understand better how the Spark dataframe operates, check the following code:
df2 = spark.read.format('delta').load('Tables/aaa_test_table')
df2 = df2.filter(F.col('active') == True)
display(df2.explain())The output looks something like this:
== Physical Plan ==
*(1) Filter (isnotnull(active#7507) AND active#7507)
+- *(1) ColumnarToRow
+- FileScan parquet [id#7505L,value#7506L,active#7507] Batched: true, DataFilters: [isnotnull(active#7507), active#7507], Format: Parquet, Location: PreparedDeltaFileIndex(1 paths)[abfss://732xxxf2-xxxx-4257-xxxx-767xxxeffxxx@onelake.dfs.fabric.m..., PartitionFilters: [], PushedFilters: [IsNotNull(active), EqualTo(active,true)], ReadSchema: struct<id:bigint,value:bigint,active:boolean>As you can see, the dataframe definition is not a physical set of data, but rather a set of instructions to tell Spark how to get data. In this case, it points to a certain storage location on OneLake, including filters. Now if we were to look at the explanation for the dataframe after running collect(), it would be:
df3 = spark.read.format('delta').load('Tables/aaa_test_table')
df3 = df3.filter(F.col('active') == True)
df3 = df3.collect()
display(df3.explain())---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[64], line 4
2 df3 = df3.filter(F.col('active') == True)
3 df3 = df3.collect()
----> 4 display(df3.explain())
AttributeError: 'list' object has no attribute 'explain'Apparently, the result of applying the collect() method to a dataframe is that its datatype is changed to a list, for which no attribute ‘explain’ exists.
Conclusion
In Spark data engineering in Microsoft Fabric, you might be tempted to make analogies between SQL Server (stored procedures) and PySpark (notebooks). While they can be made to behave the same functionally, not every concept can be translated 1:1 between the two.
Today we looked at the behaviour of temporary tables in SQL versus dataframes in Spark, where we have concluded that dataframes behave much more like views than tables. In order to make them ‘freeze’ their state and behave more like a ‘table’, we can use the collect() method on a dataframe in order to save down a hard-copy of the data.