The medallion architecture is maybe the most important concept to grasp when you start building lakehouse solutions on Microsoft Fabric.
Data products should never be built ‘right away’ or on their own. There’s a structure and process to follow. Luckily, we don’t have to figure out that structure by ourselves. Rather, I’d suggest using what has been proven over and over again by other people.
The medallion architecture is one of the most widely adopted architectures for developing data products in a modern dataplatform such as Microsoft Fabric, Synapse, or DataBricks.
In this post we’ll look at how the medallion architecture helps us, data engineers, to structure our data processing.
What is the Medallion Architecture?
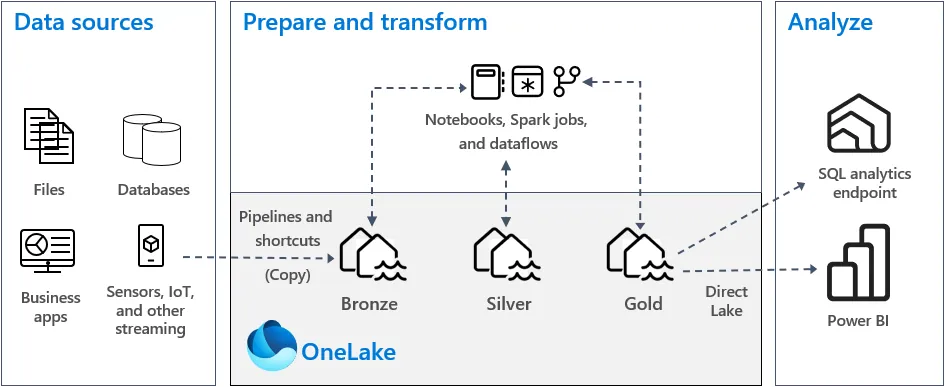
A Three-Tiered Approach to Data Processing
The medallion architecture is a so-called three-tiered approach to data processing. It describes three tiers, or stages, in a data platform where data is incrementally refined and structured from each layer to the next.
The name ‘medallion’ comes from the names given to the three layers: bronze, silver, and gold. This is just semantics by the way, you are free to name your layers 1, 2, and 3, or John, Jane, and Pikachu. However, in our company we try to create predictable and repeatable data platforms so we stick to the bronze, silver, gold naming convention.
A high-level understanding of the three layer would be that raw data is being stored in the bronze layer, in silver this data is being structured into tables with fixed columns and data types, and the actual data products are prepared in gold.
The Bronze Layer – Raw Data
What Defines the Bronze Layer?
The bronze layer in our data platform contains raw data, and raw data only!In Microsoft Fabric lakehouses, there are two types of storage.
The first is Tables, these are managed by the service, and are typically stored in delta lake format.
The second type of storage is called Files, which is unmanaged storage.
In Files, you can store everything you’d like from structured data files such as JSON and CSV to unstructured data in PDF or JPG files. As I mentioned, in the bronze lakehouse we will store raw data ingested from the source.
Whatever the data format is coming in, that’s the format we store. Many APIs these days return JSON files that we can store in the Files section of our lakehouse. Also XML, CSV and XLSX formatted data that we might receive from some APIs or processes can be stored like that.
In the case where we copy database tables, such as from SQL Server, we don’t receive a native file format. In these cases we decided to store the incoming data as PARQUET files in our bronze layer.
Next to being a store of raw data that is staged before further processing, the bronze layer in a medallion architecture also acts as a historical archive of data extracted through time. This enables us to do full restores of the data warehouse or lakehouse from scratch, as well as using the bronze layer as an audit trail on data ingested.
Folder and Data Management
In practice, the bronze layer will contain many different folders and files describing the data as it were at various moments in time, when the data was ingested into the data lake.
The very first thing I’ll do when setting up the bronze layer in the medallion is to create a folder in the root of Bronze/Files called ‘Landing’. This is the root folder of what we will consider the landing zone in bronze.
It isn’t necessary to include other folders – maybe you’ll put some logging in there, and maybe not – but the reason to make one single folder the root of your bronze landing zone is to easily shortcut all your bronze files into other lakehouses. There is, as of writing this post, no way to shortcut large batches of objects. By putting all files under a common root folder, you can simply shortcut that folder and be done with it.
Then, I will usually let the ELT process determine the folder structure that is being created for storing bronze data. What I mean by that is that I’ll let my pipelines and notebooks write data into folders with names such as Landing/20240916180255/Jira/Tickets/, containing files such as 1.json, 2.json, etcetera.
A clear patters emerges here, we start with the timestamp, then the system we’re extracting data from, then the table name or API endpoint, then files (one or multiple) containing the actual data.
It’s important to note that all of this is created by letting the pipelines and notebooks do their thing. They should have context on the timestamp in which the process runs, the name of the source system you’re pulling data from, and the table of endpoint you’re trying to copy.
Then, within those folders, I let Fabric decide what files to put there. If I’m extracting a SQL Server table there might be one or multiple PARQUET files depending on what the engine thinks is the most efficient way to partition the data. If I’m extracting data from a paginating API I might receive 10,000 rows in pages of 500 records each, so I’m storing 1.json, 2.json, …, 20.json.
Now of course, you’d want the system to create the knowledge about these folders (e.g. which timestamp, which system, table, etc) from metadata or a configuration dataset, but even if you did everything hardcoded, this is the structure I would use.
The Silver Layer – Refined Data
Purpose of the Silver Layer
In the bronze layer we left the story at ‘storing data in the raw format’, in the silver layer of our medallion that will change.
Looking at the theory of the medallion architecture, there are several things you could do in the silver layer. In my case, I usually don’t do any data transformations with business logic just yet (gold is reserved for that) but I do implement a historical archive of data (what used to be called the ‘persistent staging area or PSA’), and also I will normalise my files into delta tables and give columns the proper data types for further processing and analyis.
The silver layer therefore consists of quite a lot of logic, but everything is reusable. I do not do any processing that is project-specific or customer-specific. Rather, I loop through the freshly extracted data in the bronze layer in order to ‘paste’ that into the already existing historical information in silver.
In short, the process in silver looks like this:
1. We look up, in our configuration / metadata, which tables have been extracted. The metadata contains information on the files types that are extracted, as well as the particular timestamp, and per table the key of the table (combination of columns that makes a record a unique record).
2. Depending on the file type, we read the file or files (think paginated APIs), and flatten them (in case of JSON or XML) into a Spark dataframe. This dataframe is then merged into the target silver table.
3. The silver table now contains a flat table from the raw data we ingested earlier, with structured format (delta lake tables), and history. That is the last piece of the puzzle. The merge into silver is not a regular insert/update merge based on the table key. Rather, we lookup the record in the target silver table. If an incoming record is new, we insert a new record. If we already know the record in silver, we will not just update the existing record but rather close out the old, existing record (by putting a lineage column called Sys_ValidTo to the datetime of now), then creating a new record with a valid from datetime of now. We now have versioned our data, in effect creating a time travel possibility throughout our data platform.
Because the data in silver is stored in delta tables, the data is easily queryable for reporting and other analytical tools. This means it is not only to be used by further processing into the gold layer. No, the silver layer can also be used for ad-hoc querying and reporting to support data analysts and data scientists looking for specific information that might not be available in the gold layer.
The Gold Layer – Optimized Data for Analytics
What Happens in the medallion Gold Layer?
In our medallion architecture, the gold layer of the data platform contains the most well-refined, prepared datasets. In the past, we would have called this the ‘data warehouse’ layer, or the ‘data mart’.
This layer should contain data in a form that is easily consumed by semantic models such as Power BI. This data format is usually called a dimensional model, or a star schema.
We define fact tables (containing transactions) and dimension tables (containing context for those transactions) and model our raw data (from the silver layer) using tools such as PySpark notebooks with Python or SQL to transform our data into a star schema.
The gold layer is optimised for analysis, but it may not contain the full scope of your organisation’s data. I would usually create a dimensional model in gold to support those semantic models that are used for mass reporting. However, it might be a perfectly fine idea to have data scientists or data analysts run ad-hoc queries against your silver layer.
The gold layer, just like silver, stores data in delta lake format only.
Things we add in gold to make it a reportable data product are foreign key relations, business key validations (no data duplication!), measures, and hierarchies (prepared, flattened hierarchies for use downstream in semantic models).
Examples of Gold Data
Example tables in the gold layer of the medallion architecture are the dimDates, dimCustomers and dimProducts tables, along with fact tables such as factOrderLines and factWarehouseTransactions.
Now, keep in mind, these are just very simple examples. In practice, dimensional modelling is a science and an art that depends very much on the information needs of your organisation.
Single Source of Truth for the Business
The medallion architecture in Microsoft Fabric should help you work towards a unified data analytics platform, where the gold layer acts as the Single Source of Truth for all your organisation’s information needs.
Besides the technical implementation of this architecture, you should also spend time and effort in educating users to really start using your medallion gold layer to run reports from. If you don’t, you risk users creating other reporting outside of the agreed upon medallion architecture (maybe directly from the source, maybe from even more manual datasets) which impairs your company’s ability to have a unified view of the business.
Implementing the Medallion Architecture in Microsoft Fabric
If you’ve made it all the way to the end of this theoretical guide on designing a medallion architecture in Microsoft Fabric, hats off to you!
Now we really need to put things into practice. In order to not make this blog post an ebook, I decided to write the practical how-to in a different post in the near future. Stay tuned!
Conclusion
The medallion architecture serves as a robust framework for organising data in a structured and scalable way. This makes the medallion an essential concept for any data architect or engineer working with Microsoft Fabric.
By segmenting data into bronze, silver and gold layers, you can ensure a clear path for data refinement all the way from the raw ingestion to serving ready-to-analyse information to business users.
Stay tuned for the practical guide on how to setup the medallion architecture in your Fabric environment!
Awesome article!
Question, if you don’t mind: I’m having trouble deciding what to name and where to put my dataflows. Say I have one cleaning data from Bronze, but putting it in Gold (because no other steps are required.) Would I put it in the Silver workspace even though it’s not writing to a Silver Lakehouse? I’d really rather not expose Dataflows in my Gold workspace, that feels kind of wrong for the pristine environment I want to present. Any ideas (or naming conventions!) welcome!
Hi Henson, excellent question! We usually split up the back-end and front-end workspaces, meaning you have your data engineering and integration workloads running in workspaces for Bronze, Silver, Gold. In those workspaces, next to the Lakehouses, we also host the Pipelines and Notebooks (and in your case, Dataflows).
Then, the Semantic Model will be presented in another workspace, together with reports, that are then shared through an app.
If you don’t want that additional workspace, you can still put your Gold logic AND your Semantic Models + Reports in the Gold workspace, and use Apps to distribute the reports to end users. That way, they won’t ever see the back end code!