
When we start implementing a data lake using Microsoft Fabric, we might be tempted to start creating pipelines and notebooks right away, without thinking about design principles. However, there’s one design principle I’d like you to consider from the beginning: DRY. DRY is an acronym that stands for Don’t Repeat Yourself. In this blog post, I’m going to share with you how to implement the DRY principle in Microsoft Fabric.
Understanding the DRY Principle
What Is the DRY Principle?
The DRY principle is a software engineering design principle that is aimed at reducing repetition. As data engineers, we can learn a lot from software engineers and this is a prime example.
DRY, or Don’t Repeat Yourself, enhances code maintainability and it facilitates scalability. These are objectives we all should strive for when designing or building data platforms using Microsoft Fabric.
The Philosophy Behind DRY
The Don’t Repeat Yourself (DRY) principle is a fundamental concept in software development that advocates for minimising code repetition. It was introduced in The Pragmatic Programmer and in emphasises that every piece of knowledge or logic should have a single, clear representation within a system.
By consolidating repetitive code into reusable functions, modules etc, developers ensure that changes need to be made only once.
Within Microsoft Fabric, we can implement the DRY principle by putting our data engineering code in custom Python modules and reusing them instead of writing repetitive data pipelines or PySpark notebooks.
Benefits of Implementing DRY
The benefits of implementing the DRY principle in Microsoft Fabric are threefold. First, it drives efficiency by preventing ‘double work’. You build something once, and then reuse it over and over.
Second, it reduces the volume of code you produce. That makes maintenance easier, and reduces technical debt.
Third, it enforces developer’s guidelines. There will be no ‘developer handwriting’ in the solution, because everything is created in the exact same way. That makes it easier to share work between colleagues and to scale up your team from 1 or 2 persons to 10 or more.
Implementing the DRY Principle in Microsoft Fabric
Overview of the Solution
Within Microsoft Fabric, I would advocate to creating a code-first approach to data engineering. In the era of low-code that might sound strange, but code has the benefit of (usually) better performance and lower compute cost. Also, it’s easier to parametrise, reuse and automate a code-first solution in my opinion.
That makes it easy to choose the technology: PySpark notebooks for data engineer as much as possible. We will probably still use data pipelines for orchestration (or potentially use notebook orchestration), but as much of the actual work as possible should be done in notebooks.
Enter: custom Python modules. By creating abstracted versions of the processes and functions you need for common data engineering tasks (calling an API and storing the JSON-documents in OneLake, or performing an upsert/merge statement, for example) you can distribute them using Python wheel files (a packaged Python project) to Microsoft Fabric.
Benefits of Custom Modules
The benefit of using modules in a wheel file that you distribute to Fabric environments, is that the code is truly reusable. In Fabric, there are other ways to reuse code, but they are, in my mind, not as well-suited as wheel files in an environment.
One of the ways to share code with Fabric is to put files in the notebook resources section of a notebook. However, that makes the code very local to the notebook, whereas the Fabric environment route will ensure that many notebooks can import code from the same wheel file.
Step-by-Step Guide to Creating Reusable Python Modules
After reading the introduction you might want to read all about actually implementing a the DRY principle in Microsoft Fabric using a custom Python module. Let’s look at how we can achieve this.
1. Creating a Custom Python Module
First, we need to start setting up the Python project on our local environment. I prefer working with Visual Studio Code, a lightweight and free development environment in which we can create Python projects, interact with source control in Git / Azure DevOps, and can access the terminal to actually run the Python functions.
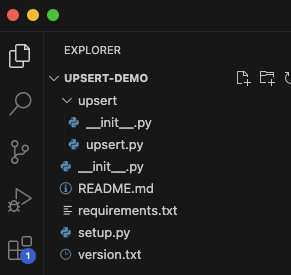
In the screenshot above we can see the setup of our demo project in VS Code. The project folder is called ‘UPSERT-DEMO’ and contains all the code and other files needed to create a Python module that we can import into Microsoft Fabric.
The file called upsert.py is the actual module. In a project, we can have many modules. In today’s example, we will have just this one. The folder called ‘upsert’, that contains the .py file and an __init__.py, is called a ‘package’ or ‘sub package’ (because in this case, UPSERT-DEMO can also be considered a package).
From the files you see, a few are important to have in your project.
First, is the setup.py. This file contains information on your module.
import os
from setuptools import setup, find_packages
current_directory = os.path.abspath(os.path.dirname(__file__))
version_file_path = os.path.join(current_directory, 'version.txt')
with open(version_file_path, 'r') as version_file:
version = version_file.read().strip()
with open("README.md", "r") as fh:
long_description = fh.read()
setup(
name='upsert-demo',
version=version,
author="That Fabric Guy",
author_email='donotmailme@thatfabricguy.com',
description="A demo for this awesome blog.",
long_description=long_description,
long_description_content_type='text/markdown',
packages=find_packages(),
classifiers=[
"Programming Language :: Python :: 3",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
],
python_requires='>=3.7',
)Feel free to change this to your needs. As you can see, the setup.py calls the version.txt file that in my case just contains the text ‘1.0’ but in practice can be your actual version or build number.
Then, we have requirements.txt, which contains a list of the imported Python code that you’ve used in your project. In my case requirements.txt contains the following text:
delta.tables
os
setuptoolsThe final important file in the project is the __init__.py in the project root folder. It contains the following code:
from .upsert import *
__all__ = ['upsert']When we create the wheel file to distribute our code as a packaged solution, this file will tell the system what to package. In this case we refer simply to the upsert module I spoke about earlier.
Our sub package ‘upsert’ also contains an __init__.py, which lists the methods in the module upsert.py.
from .upsert import (
upsert
)
__all__ = [
'upsert'
]If we would have more methods in the module, this file would list them all.
Then, finally, we arrive at the actual code we’re going to reuse. In this example that would be:
# Imports
from delta.tables import *
def upsert(spark_session, dataframe, table_name, table_keys):
if DeltaTable.isDeltaTable(spark_session, f"Tables/{table_name}"):
# perform upsert
delta_table = DeltaTable.forName(spark_session, table_name)
merge_condition = ' AND '.join([f"target.{key} = source.{key}" for key in table_keys])
# Perform the merge
delta_table.alias('target').merge(
source=dataframe.alias('source'),
condition=merge_condition
).whenMatchedUpdateAll() \
.whenNotMatchedInsertAll() \
.execute()
else:
# copy df to delta
dataframe.write.format("delta").saveAsTable(table_name)The actual code is not part of the scope of this blog post, however, it isn’t that difficult to understand. On line 5 we check whether a delta table already exists for the given table_name, if it does, the code performs an upsert, if it doesn’t, it will create the delta table.
However simple this is, you can imagine a much more complex scenario where many methods are created to be reused in a data engineering project.
2. Packaging the Module for Microsoft Fabric
In order to actually use the code in our Fabric environment, we will need to package our Python code into a distribution, through a wheel file.
In practice, I will usually setup a build pipeline in Azure DevOps. That way, we can do source control and versioning on our custom Python modules. This build pipeline will then generate a build artefact, which is the wheel file we want to distribute.
For today’s example, we will simply create the wheel file from the terminal in VS Code. In order to do so, we need to have Python 3 installed on our local machine, and then run the following terminal command:
python3 setup.py bdist_wheelRunning this command looks like this:
Doing so, will create the following (highlighted folders) folders and files:
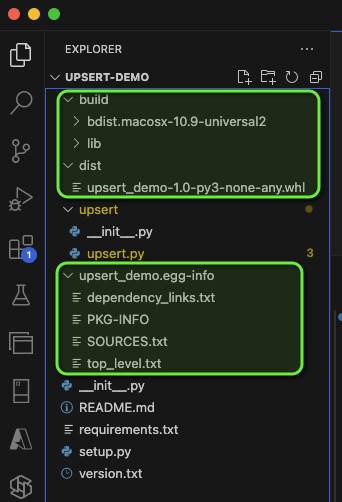
The file we’re interested in is the .whl file under ‘dist’. The name of this file is driven by the setup.py file, you can see that the project name and version are used in the name of the wheel file.
3. Importing and Using the Module in Notebooks
Next up, we need to go to Fabric, navigate to our workspace, and create a new ‘Environment’ artefact.
Then, within the Environment, navigate to custom libraries and upload the wheel file you just created. Then, save and publish the Environment. Mind you: publishing might take 10-15 minutes so be patient and grab yourself a coffee while you wait.
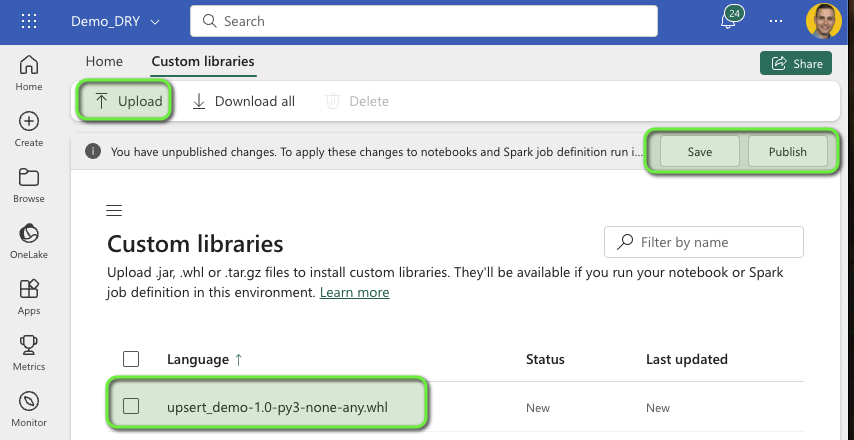
Now that you’ve finished your coffee and your Environment is published, let’s look at how to implement your code in a notebook!
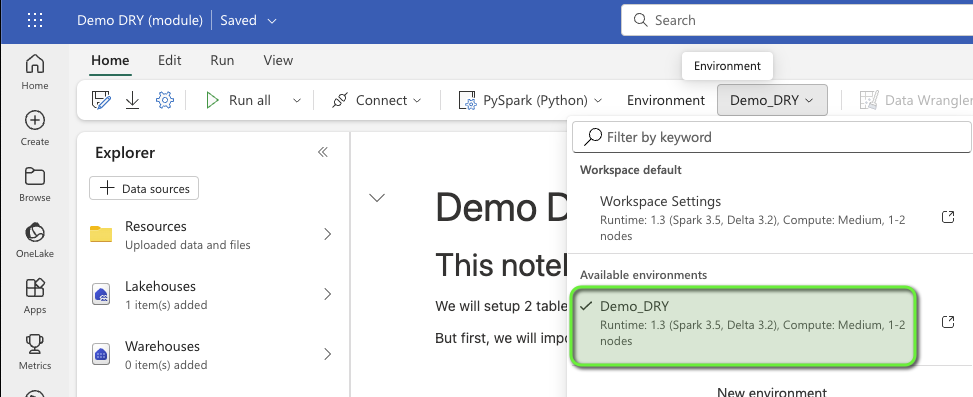
Head over to a notebook (existing or new, doesn’t matter). First of all, we’re making sure the notebook executes within the environment we just created! You can do so by setting the workspace’s default environment, or by setting the notebook environment:
Then, in the first cell in the notebook, I put the following code that imports the upsert package:
# Import
import upsert as upNote that I created an alias ‘up’, which means I can call methods from my package using ‘up.<method name>’. You can give aliases as you prefer.
Now, in the notebook cells, I can start upserting data like:
# Initial load of user table
table_name = "users"
table_keys = ["ID"]
columns = ['ID', 'Name', 'Age']
data = [
(1, 'Alice', 28),
(2, 'Bob', 35),
(3, 'Charlie', 23)
]
df = spark.createDataFrame(data, columns)
# Create delta table
up.upsert(
spark_session = spark,
dataframe = df,
table_name = table_name,
table_keys = table_keys
)Which in turn will create or update/insert a dataframe into a delta table in my lakehouse. All without having local code in my notebook.
This exact same code can be called by many notebooks, by many different data engineers or developers. When we decide to make changes to the code itself, we only need to do so inside VS Code, create a new wheel file, and publish that to the environment. No need to update all your notebooks, that will happen automatically!
Conclusion
Implementing the DRY (Don’t Repeat Yourself) principle in Microsoft Fabric is a very interesting tactic that elevates your data engineering projects to new levels of efficiency and maintainability. By adopting a code-first approach with PySpark notebooks and leveraging custom Python modules packaged as wheel files, you eliminate redundancy and promote code reuse across your data pipelines.
This not only reduces the volume of code by making maintenance easier and decreasing technical debt, but also enforces consistent development practices among your team. Distributing your modules through Fabric environments ensures that all notebooks have access to the same robust functions, facilitating collaboration and scalability.
Frequently Asked Questions about DRY principle in Microsoft Fabric
• Create Your Module: Write your reusable functions in a Python file (e.g., my_module.py).
• Package as a Wheel File: Use setup.py and wheel to package your module (python setup.py bdist_wheel).
• Upload to Microsoft Fabric: In Fabric, create an Environment and upload the .whl file under Custom Libraries.
• Import in Notebooks: In your notebook, set the environment to the one with your module and import it using import my_module.
• Efficiency: Write code once and reuse it, saving time.
• Maintainability: Easier to update centralized code.
• Consistency: Uniform codebase across projects and teams.
• Scalability: Simplifies expanding projects and onboarding new team members.
• Yes, You Can: Use external libraries that are available in the Fabric environment.
• Manage Dependencies: Include required libraries in your setup.py or requirements.txt.
• Installing Libraries: If needed, install libraries in your notebook using %pip install library-name.
• Use Git: Store your module code in a Git repository (e.g., GitHub, Azure Repos).
• Versioning: Apply semantic versioning (e.g., v1.0.0) in your setup.py.
• Collaborate: Use branches and pull requests for code changes.
• Update Modules: Pull updates into the Fabric environment as needed.
• Write Docstrings: Document functions and classes with clear explanations.
• Maintain a README: Provide installation instructions and usage examples.
• Consistent Style: Follow standard documentation practices (e.g., PEP 257).
• Include Examples: Offer sample code or notebooks demonstrating module usage.
• Code Review: Regularly check your code for vulnerabilities.
• Access Control: Set permissions to prevent unauthorized access.
• Handle Secrets Safely: Avoid hardcoding credentials; use secure storage methods.
• Update Dependencies: Keep external libraries up-to-date to mitigate risks.
Hi, great post!
When developing the merge function locally, how do you test it to make sure it works? Do you first develop it in a notebook in fabric and then paste it locally?
Thanks in advance.
Hi Johan, my apologies for the delayed answer. In most cases, I will develop and test new functions in a live notebook, in order to quickly see results and validate outputs. Once that is done, I’ll port it over to the Python project in VS Code. From there, it will enter our DevOps workflow (pull request approval, build, etc).
Just make sure to include a reference to your spark session object (parameter “spark = spark”) even in your live notebook. While it’s not necessary there (the notebook already runs within that spark session), it makes copying the solution over to Python much easier.