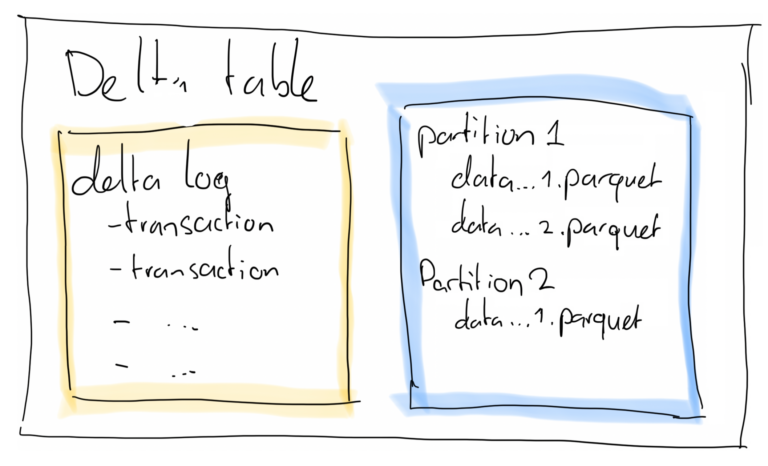
Delta Lake Liquid Clustering vs Partitioning
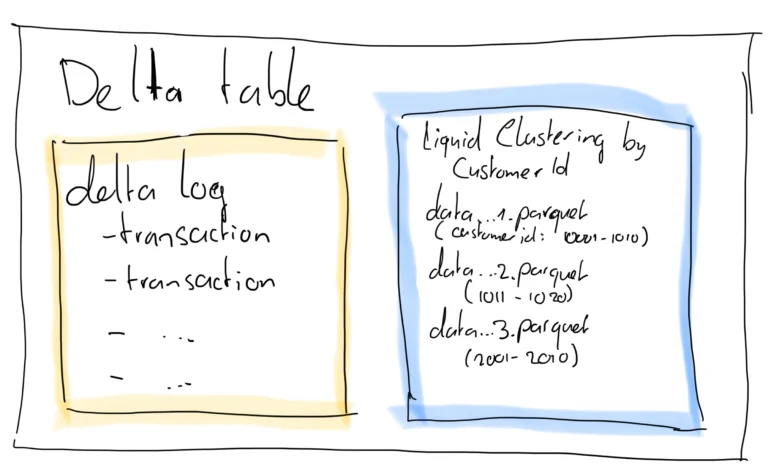
Introduction to Delta Lake Liquid Clustering As your Delta tables grow in size, the need for performance tuning in Microsoft Fabric becomes essential. In this post, I’ll explore two powerful optimisation techniques — Delta Lake Partitioning and Liquid Clustering. Both can help improve query speed and reduce costs, but they work in very different ways. …