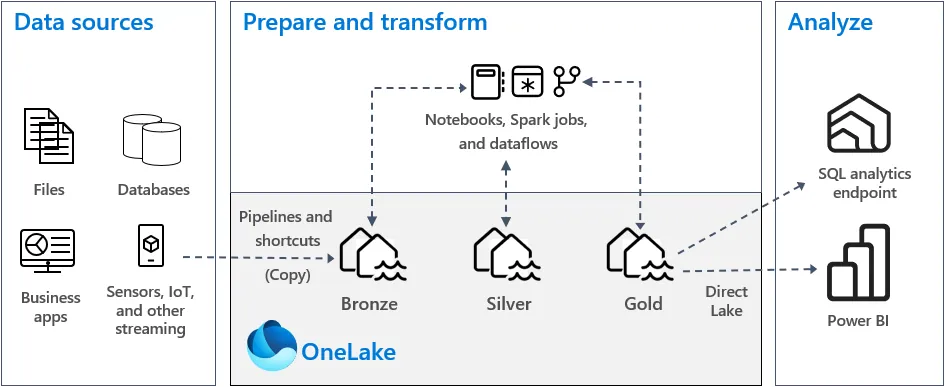
Introduction
In this guide, we’ll dive straight into the practical steps of how to implement Medallion Lakehouses using Microsoft Fabric. If you’re unfamiliar with the Medallion Architecture, or need a refresher, check out our previous post on the theory behind the Medallion Architecture.
This post focuses on hands-on implementation, guiding you through each step of setting up Bronze, Silver, and Gold layers in Microsoft Fabric. By the end, you’ll be able to create a scalable, performant, and secure lakehouse. Let’s get started!
Setting Up the Fabric Environment
In this post I will assume you already have a Fabric tenant up and running. If you don’t, please create one first! You can signup for a free trial yourself or you can talk to your favourite consultant to help you out. Give me a shout and I will guide you 😉
Is your Fabric tenant ready? Great. Let’s go!
Workspace Setup
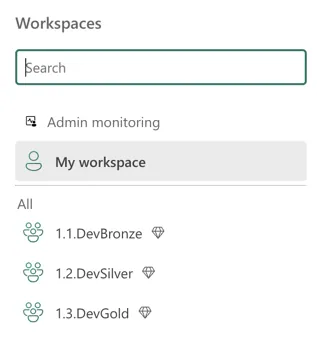
For a medallion architecture I will always choose to create separate workspaces for the three stages of the medallion. That means that there will be a Bronze, Silver, and Gold workspace in the Fabric portal.
Creating the workspaces is very straightforward. You can simply click the ‘create workspace’ button and then choose a name and fill in the licensing type. My example is in the image below.
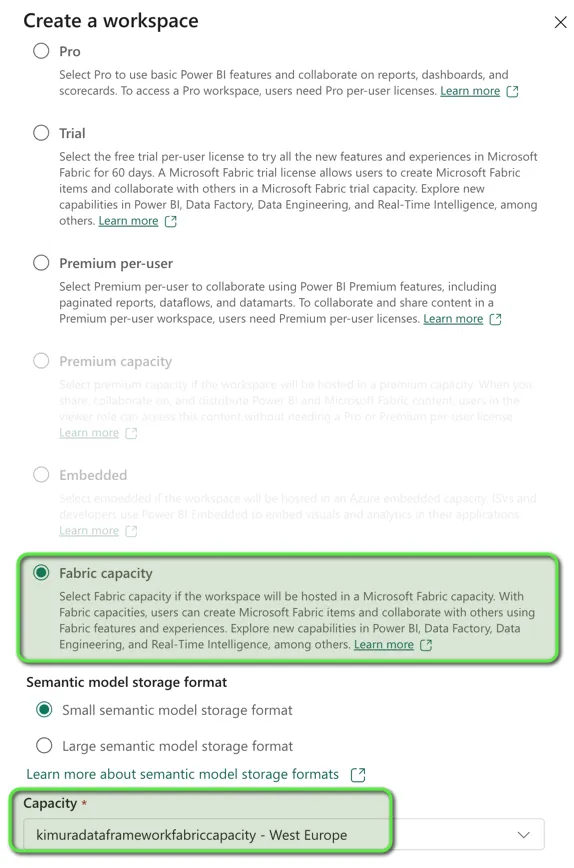
Here you see you just need to pay attention to two settings. The first is the license type, which you will set to ‘Fabric capacity’, the second is choosing the capacity. In this example, the account I used to create the workspace was capacity admin of just this one capacity, so it was automatically selected. Note that if you are a capacity admin of multiple capacities, you can choose which one you want to use in this workspace.
As I said, I will create a workspace per medallion layer so usually I would end up with something like this:
Bronze Layer: Raw Data Ingestion
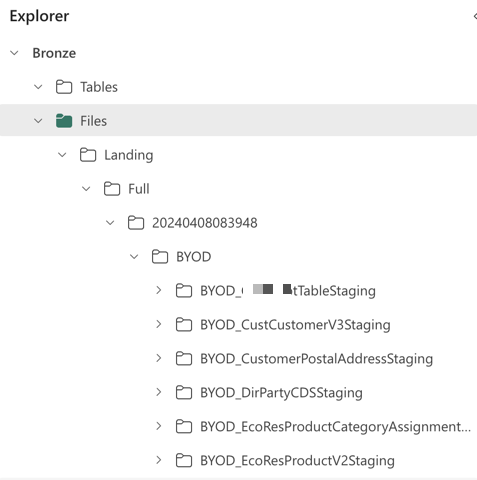
In all my dataplatforms, I use the Bronze layer in the medallion to store raw data only. When my pipelines or notebooks are ingesting data, they store that data in a Bronze lakehouse. Specifically, in the Files section of the lakehouse.
As you might know, Fabric Lakehouses come with two separate ‘areas’: Tables and Files. Tables is the managed part of the lakehouse, where you can store delta tables. Files is the unmanaged part where you can store what ever file you like.
Now usually I don’t go running around using file formats I like, rather, I choose to store data in the exact file format that I receive. From most APIs, that’s JSON, but it could also be a CSV download from somewhere, or PARQUET when reading from a SQL database.
Those files are neatly organised in folders, according to load type (full or incremental), timestamp (I always use a 14-digit year through second timestamp in yyyymmddhhmmss format, source system, table/endpoint.
Please note that I will put the table or endpoint in a folder not in a file. The reason is that, sometimes, files for a single table or endpoint within a single load need to be split up. This can happen when PARQUET files loaded from a database become very large and the engine decides to split them. It also happens quite often for APIs that you need to paginate through, you might end up with a 1.json, 2.json, etc, in a folder for the endpoint.
Silver Layer: Data Standardisation
When I implement medallion, I will usually perform data standardisation in the Silver layer. The raw files that we have in the Bronze layer will be transformed into delta tables in Silver. This makes it easier to query them later on for analysis. I will also perform data type standardisation and create a historical archive (previously called persistent staging area) in the Silver layer.
Whereas in the Bronze layer I would use Pipelines or Notebooks to ingest data into the lakehouse, I will use Notebooks exclusively to implement the Silver medallion.
Implement Medallion Silver layer using PySpark notebooks
Because I will not perform any client-specific, or even table-specific, data transformations in the Silver layer, this part of the lakehouse is fully standardised and automated. Within the Fabric environment I have a custom Python library containing reusable code, that I can call from a Notebook.
The Notebook will usually be split into two parts. The first part is called the Orchestrator and will figure out (based on metadata) which Bronze tables or endpoints have been ingested in this run. It will then call the second Notebook (called the Worker) many times in parallel in order to actually process data.
The Worker Notebook will call Python methods from the custom library that will do the heavy lifting: checking whether a delta table already exists, creating it if necessary, loading new data from Bronze, and performing a persistent load by checking if an existing record is coming in again (and is changed) so that it can load a new version of that record.
Gold Layer: Optimising for Analytics
Then, after loading data to the Silver layer, we can finally implement the Medallion Gold layer. In the Gold layer data is modeled in a way such that it can be consumed easily by front-end analytics applications such as Power BI semantic models.
That means that we will model the data into star schemas, or facts and dimensions.
Dimensional Modelling and Star Schemas
Dimensional modelling means to organise your data into fact tables containing transactions, usually on line level, that can be aggregated (count of orders, sum of revenue, etc). Using a fact table in a report will result in a number (1,000 pieces of product shipped).
The plain number is usually not very useful to the end user of the report or dashboard. There must be context around the numbers. That is where dimensions come in. A dimension contains contextual information about the transactions in your dimensional model. Typical dimensions are the Dates, Customers, and Products.
In order to implement the medallion Gold layer we will create several PySpark notebooks, one per table (fact or dim). In the same fashion as with Silver, I implement this using an Orchestrator and Worker notebook, but in this case, there are many workers (one per Gold table).
The Worker notebooks for Gold contain mapping queries, queries that read data from Silver and shape it such that it can be fed into the Gold layer as facts and dims.
Power BI Integration
The integration of data into Power BI (or any other front-end BI tool) will happen on the Gold layer. The delta tables in Gold are the tables that are loaded into the Power BI semantic model, usually using Power BI’s DirectLake mode but sometimes Import mode in the SQL endpoint of the lakehouse also works well.
I don’t really want Power BI to be connected to other Medallion layers than Gold, for the simple reason that the Gold layer is optimised for semantic modelling by producing a dimensional data model.
In Gold, we can also easily add business logic to the data in order to make reporting in Power BI easier, whereas Silver contains just the raw data from the different data sources.
Data Governance and Security
This article discussed implementing Medallion layers in Microsoft Fabric. In my examples, I showed how I separate the three layers into not only separate lakehouses, but also separate workspaces. The reason for that is to govern and secure the data in my data platform.
In the Fabric portal, usually people will be given access to workspaces based on security groups in Entra ID. By separating Bronze, Silver, and Gold into separate workspaces, we can now give different Entra ID groups access to those objects.
That means that my business analysts might get access to the Gold layer in order to create new semantic models and drive insights. A data scientist might also want to request access to the Silver layer when having historical information is beneficial to a specific analysis or machine learning model.
By splitting the Medallion layers into separate workspaces, it becomes very easy to secure your data while enabling people in the organisation to make use of the insights the data produce.
Conclusion
Implementing a Medallion Lakehouse in Microsoft Fabric can significantly enhance the scalability, performance, and security of your data architecture. By organizing data into Bronze, Silver, and Gold layers, you ensure that raw data is ingested efficiently, transformed into clean and standardized formats, and optimized for analytics and reporting.
With proper workspace separation, governance, and Power BI integration, this approach empowers your team to unlock insights and drive data-driven decisions. Now it’s time to apply these practical steps and build your own Fabric Lakehouse!
Please let me know how you implemented Medallion in your organisation!
Would you need to create nine workspaces with nine lakehouses e.g. DevBronze, DevSilver, DevGold, TestBronze…. ProdGold? How do you implement the equivalent of a deployment pipeline when using Lakehouses to control when you are ready to move notebooks and pipelines?
Great question! The answer might be a bit too much for a comment here, though. It warrants its own post I’d think. I’ve put it on my to-write backlog! 🙂
I would like to know how can we create CI CD pipeline in this case.
Hi Siddhant, you would usually set up multiple workspaces (one per environment per medallion stage) and use Fabric Deployment Pipelines to move objects from Dev to Test to Prod. I will probably write a blog article on this in the future, but I don’t know when that will be.