Introduction to Delta Lake Liquid Clustering
As your Delta tables grow in size, the need for performance tuning in Microsoft Fabric becomes essential. In this post, I’ll explore two powerful optimisation techniques — Delta Lake Partitioning and Liquid Clustering. Both can help improve query speed and reduce costs, but they work in very different ways.
We’ll break them down, compare them, and help you decide which one fits your scenario best. Earlier, I already wrote about partitioning, so I will focus on liquid clustering today and compare that to partitioning.
Reminder: What is Delta Lake Partitioning?
Partitioning is the classic way to optimise large Delta tables. It splits your data physically into subfolders based on one or more columns — often a date or category.
If your query filters on the partitioned columns, only relevant partitions are scanned, which can dramatically speed things up. However, this approach comes with trade-offs that we’ve mentioned in the post on partitioning.
What is Liquid Clustering in Delta Lake?
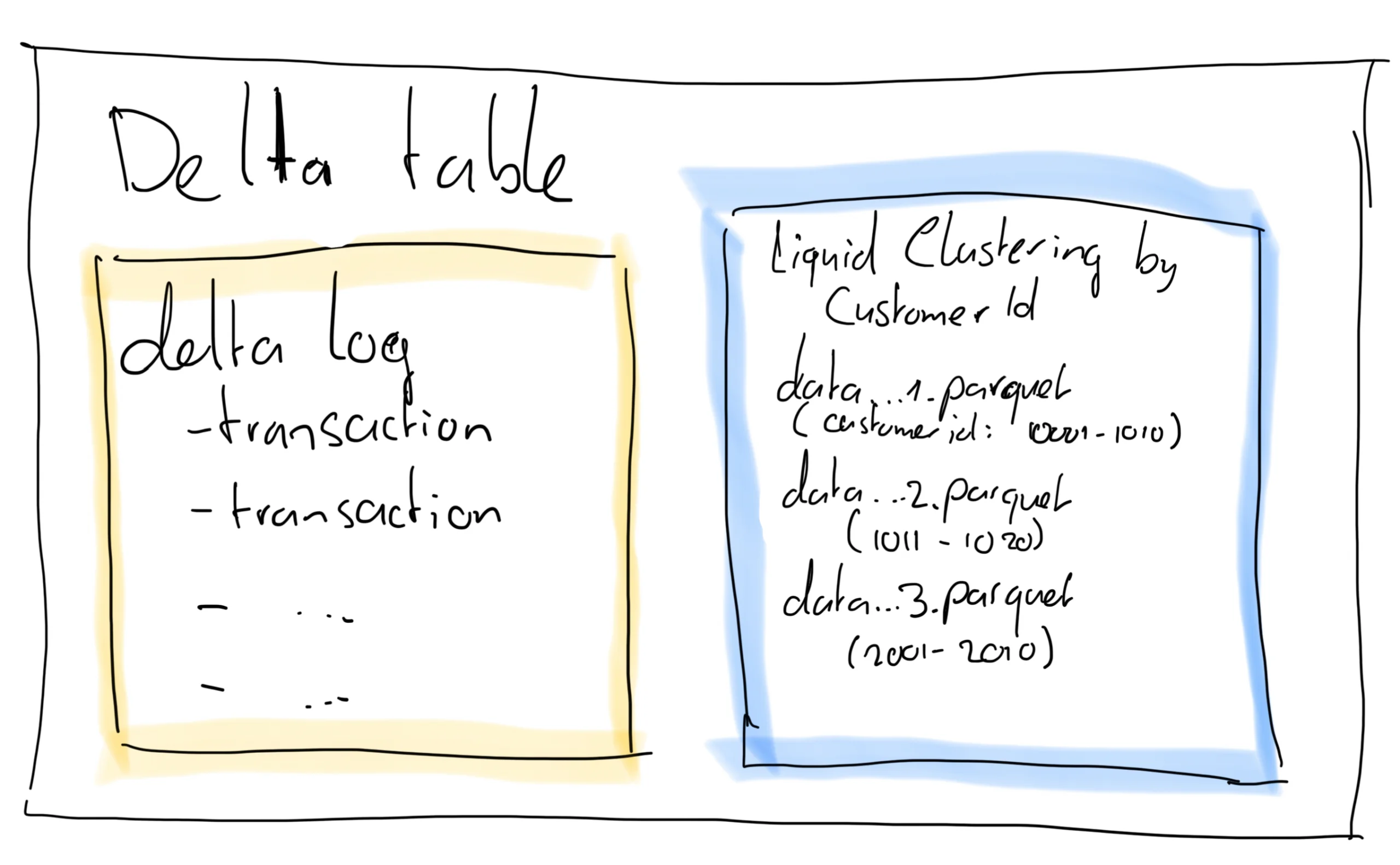
Liquid Clustering is a newer, more dynamic approach available in Delta Lake and therefore in Microsoft Fabric. Instead of physically splitting data into folders like traditional partitioning does, Liquid Clustering logically clusters your data by values in one or more columns — all without changing the table’s physical layout.
So what does that mean in practice? Under the hood, Liquid Clustering organises your data into what’s effectively a logical sort order during writes. It groups together rows with similar values in the clustering columns. These grouped rows end up stored in the same files or file ranges. Then, when you run queries with filters on those clustered columns, Spark can quickly skip over unrelated data by consulting file-level statistics (like min and max values for each file).
This behaviour is very similar to Z-Ordering in traditional Delta Lake, but with two big differences: you don’t need to explicitly run a maintenance command like OPTIMIZE ZORDER BY, and the clustering is maintained incrementally with each write. In effect, Liquid Clustering creates a kind of soft indexing on your data — it doesn’t guarantee perfect ordering, but it improves data locality, reduces I/O, and allows Spark to prune files much more efficiently at query time.
The result? Faster queries, especially on large tables with high-cardinality filter columns like product IDs, user IDs, or timestamps — and far less engineering effort to maintain it.
Partitioning vs Liquid Clustering – How They Work Under the Hood
Storage Layout
Partitioning results in physical folders like /PickupDate=2025-04-01/. Clustering, on the other hand, leaves your data in place but adds metadata about how it’s logically grouped.
Write-Time Complexity
Partitioning must be defined when the table is created. Changing it later involves rewriting the data. Liquid Clustering allows for adjustments without reloading the whole table. This makes maintenance much easier, and I like that!
Query-Time Optimisation
Both techniques enable data skipping, but the mechanics differ. Partitioning uses folder-based pruning, and Liquid Clustering relies on Spark’s file statistics to skip files. This also implies you need quite large tables before Liquid Clustering starts to make sense. Because if you can compact your delta table into one single parquet file, clustering won’t add any benefits.
Maintenance Effort
Partitioning requires careful planning and can degrade performance if overused. Liquid Clustering is more forgiving and easier to evolve over time.
Performance Considerations
We’ve tested both approaches on large datasets — in some cases with billions of rows — and the results may surprise you.
For highly selective filters (e.g. one day’s worth of data), partitioning often wins. But for broader queries or when filter values vary, Liquid Clustering can shine thanks to its adaptive design.
Querying a Single Partition
Partitioning performs well here. Spark scans only what it needs which is fast and efficient. In the previous post we saw good improvements in read performance for this exact scenario on a very large scale table (± 4 billion rows).
Querying Across Many Partitions
This is where partitioning can backfire. Reading hundreds of small files adds overhead, whereas Liquid Clustering can streamline the process. We have seen this in the previous post as well, where reading data over multiple partitions actually took longer than the same query on the unpartitioned table.
Liquid clustering has less problems in this scenario, because it doesn’t necessarily split the data into to too many small files. Rather, it keeps the file size in Spark’s optimum, and based on your query, selects the appropriate files it expects the data in.
Full Table Scans
When scanning all data, partitions add no benefit — and might even slow things down. Clustering keeps things leaner. But even then, I expect not that big of a difference with clustering versus a not optimised table.
Best Practices for Partitioning
- Use only when your query patterns consistently filter on the partition key.
- Choose low-cardinality columns (like date or category) to avoid file explosion. And even then, be wary. Keys like data could quickly blow up on tables with lots of history, and if your filters usually are on year and month, partitioning on date won’t do a thing.
- Avoid partitioning small or medium sized tables because the overhead isn’t worth it. Only the largest tables benefit from partitioning.
- Once set, changing the partitioning requires rewriting the entire table. This is a major drawback.
Best Practices for Liquid Clustering
- Use it when queries vary or evolve over time.
- Apply Liquid Clustering to high-cardinality columns without performance penalties.
- Also easy to use if you plan on minimising your maintenance efforts.
- Liquid Clustering can be ideal when working with medium sized tables.
Can I Use Both?
Absolutely. A hybrid approach is often the sweet spot.
For example, coarse partitioning by year, combined with Liquid Clustering by product or region, can give you the best of both worlds. Just make sure your query patterns align with how your data is structured and clustered.
When to Use Liquid Clustering or Partitioning for Delta Lake?
The choice between these two techniques is largely driven by the factors I’ve mentioned above in this article. But another big factor we haven’t discussed yet is the table size.
As mentioned, the partitioning of small tables is not efficient because of the overhead when reading from multiple small files. Spark prefers larger Parquet files, so too much partitioning doesn’t work that well.
The same goes for liquid clustering, where file elimination is triggered based on the metadata of those files. If there are just 1-2 files in a delta table, this will not make sense.
From research, I’ve found the following general guidelines. There is no definitive answer as to which strategy to use for which table size, but when looking at the orders of magnitude you can come to the following guidelines:
| Table size / row count | Optimisation strategy |
| < 1 GB / < 10 million rows | Nothing – keep things simple! |
| 10-100 GB / 10-100 million rows | Liquid Clustering based on columns that are often used in filters |
| > 100 GB / billion+ rows | Partitioning + Liquid Clustering |
How To Create Liquid Clustering in Microsoft Fabric Delta Tables
Creating new Delta tables with Liquid Clustering is quite easy! Just refer to the below example. In the second-last line, you see that we call the .clusterBy() method to enable clustering on these columns. It’s as easy as that!
#ClusteringDateTaxiType
DeltaTable.create(spark) \
.tableName("gold_facttaxidata_ClusteringDateTaxitype") \
.addColumn("PickupDate", "DATE") \
.addColumn("PickUpTime", "STRING") \
.addColumn("DropoffDate", "DATE") \
.addColumn("DropoffTime", "STRING") \
.addColumn("PickupLocationId", "INT") \
.addColumn("DropoffLocationId", "INT") \
.addColumn("TaxiTypeId", "INT") \
.addColumn("PassengerCount", "INT") \
.addColumn("TripDistance", "DOUBLE") \
.addColumn("FareAmount", "DOUBLE") \
.addColumn("SurchargeAmount", "DOUBLE") \
.addColumn("MTATaxAmount", "DOUBLE") \
.addColumn("TipAmount", "DOUBLE") \
.addColumn("TollsAmount", "DOUBLE") \
.addColumn("ExtraAmount", "DOUBLE") \
.addColumn("EhailFeeAmount", "DOUBLE") \
.addColumn("AirportFeeAmount", "DOUBLE") \
.addColumn("CongestionSurchargeAmount", "DOUBLE") \
.addColumn("ImprovementSurchargeAmount", "DOUBLE") \
.addColumn("_PickupYear", "INT", generatedAlwaysAs="YEAR(PickupDate)") \
.addColumn("_PickupMonth", "INT", generatedAlwaysAs="MONTH(PickupDate)") \
.clusterBy("PickupDate", "TaxiTypeId") \
.execute()Maintenance for Liquid Clustering on Delta Tables
Simply running the OPTIMIZE command against your table will trigger the clustering. I usually have a maintenance job that I run once per week, in order to COMPACT, OPTIMIZE and VACUUM my tables.
For tables that are updated very frequently (think multiple times per hour), you might want to experiment with daily maintenance jobs. However, keep in mind that maintenance introduces overhead compute usage.
Conclusion
Whether you lean towards partitioning or embrace the flexibility of Liquid Clustering, the key takeaway is this: there’s no silver bullet. Each approach has its strengths and weaknesses. Partitioning can offer fast query performance when done right, but it’s rigid and difficult to maintain. Liquid Clustering, on the other hand, brings adaptability and ease of use, particularly as your data volumes grow and usage patterns change over time..
In most real-world scenarios, a thoughtful combination of the two will give you the best results. Start simple, monitor your query patterns, and don’t be afraid to iterate. As always in data engineering, context is king, so let your use case guide your optimisation strategy.
And as always, if you need any help with Microsoft Fabric, let me know in the comments below or send me a personal message!