Coming from the ‘old school’ world of SSIS and SQL Server, and later Azure Data Factory and Azure SQL Database, I have always built my ETL orchestration processes using some kind of pipelines. In Fabric, we also have pipelines (the successor of ADF), but, we can now also create notebook orchestration using NotebookUtils and runMultiple().
Metadata driven Notebook Orchestration
In ADF, I always made sure to have metadata driven pipelines for orchestration, with a configuration database in which information is stored that describes the ETL processes that were run. My old framework consisted of a hierarchical description of source systems, tables, and (optionally) table columns to extract, including things like incremental loads, configurations of API endpoints and so on.
Also on the DWH transformation side of the ETL we had a similar setup, with tables, the corresponding stored procedures, and configurable information about how tables could be loaded sequentially or in parallel.
Nowadays, we do the same thing in Fabric Pipelines, in order to orchestrate the ELT process that loads data through the medallion architecture.
However, we have run into some issues that I would like to address in this blog post.
Issues With Parallel Orchestration of Notebooks using Pipelines
When you start creating a metadata driven framework using a configuration database and pipelines, you will find yourself creating some kind of version of the following pipeline:
<img of lookup and foreach>
However, if you do so to start a notebook within the foreach loop, you will quickly run into an error saying that you have too many concurrent Spark sessions. So, that doesn’t work.
High Concurrency Notebook Sessions should solve this issue, but as far as I’m aware, this feature is still on the roadmap and not available for Fabric yet.
So, we need to do something else. That something is creating a notebook orchestrator, in a notebook 🙂
Using Notebooks to Orchestrate Notebooks in Fabric
As a way around this, we could use notebooks to orchestrate parallel processing loads in Microsoft Fabric. We will use a Python package called NotebookUtils (formerly called MSSparkUtils) that’s created by Microsoft. Specifically, we will use the method runMultiple() in this package, to tell the notebook to start multiple notebooks in a certain fashion (parallelised, with dependencies, etc).
In practice, I will use this to create a fully parallel load of the Silver layer in our lakehouse, and to create a partially parallel load of the Gold layer in the lakehouse.
Let’s look at Silver for the time being. Because I have created a custom Python library with code to generate the Silver layer based on metadata, I don’t need to write a custom notebook for every table in Silver. Rather, I can read metadata (from a config database, or a json file) and loop through that, telling a generalised Silver notebook what to do.
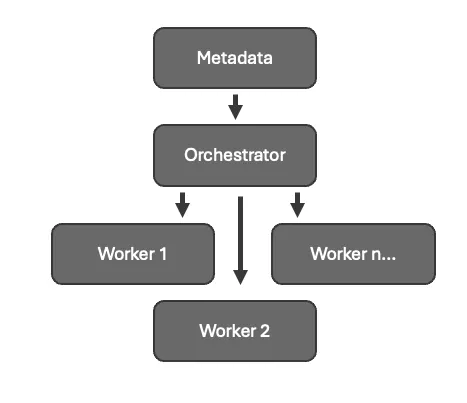
The solution, therefore, is a three stage rocket. Stage 1 is the Silver Orchestrator notebook. Stage 2 is the Silver Worker notebook. Stage 3 is the custom Python library that does the actual work.
I will describe the first stage here in a simplified setting to make the concept clear. The actual contents of the Silver Worker notebook in stage 2 and the Python library in stage 3 don’t matter – you can call any kind of method from your Python environment using this Orchestrator and Worker notebook pair.
Silver Orchestrator Notebook using runMultiple
The Silver Orchestrator notebook will lookup metadata about the Bronze data to process to Silver. In practice, I will most likely have a json file in the lakehouse that stores this metadata. In the example below I have included a rather simple set in Python directly.
table_list = [
{'TargetTable': 'A1', 'SourceSystem': 'A', 'TableKey': 'Id'},
{'TargetTable': 'A2', 'SourceSystem': 'A', 'TableKey': 'Id'},
{'TargetTable': 'A3', 'SourceSystem': 'A', 'TableKey': 'Id'},
{'TargetTable': 'B1', 'SourceSystem': 'B', 'TableKey': 'Id'},
{'TargetTable': 'B2', 'SourceSystem': 'B', 'TableKey': 'Id'},
]
activities = []
#Load data to Silver layer delta tables
for table in table_list:
target_table = table['TargetTable']
source_system = table['SourceSystem']
table_key_list = table['TableKey']
args = {
'target_table': target_table,
'source_system': source_system,
'table_key_list': table_key_list
}
activity = {
'name': target_table,
'path': 'Silver_Worker',
'args': args,
'timeoutPerCellInSeconds': 9000,
'retry': 1,
'retryIntervalInSeconds': 10,
'dependencies': []
}
activities.append(activity)
DAG = {
'activities': activities,
'timeoutInSeconds': 43200,
'concurrency': 50
}
#Execute
#notebookutils.notebook.runMultiple(DAG)
display(DAG)

As you can see, we create a DAG (Directed Acyclical Graph) containing information on the objects we want to process, the parallelism settings, and the dependencies.
The DAG consists of activities and metadata. The metadata describes the timeout and concurrency. You can see those at lines 36 and 37 in the example above. The activities is an object that gets created by appending the activity object to the activities list. An activity contains information about a task that needs to be executed. In this case it describes the name (set to the target_table variable, the name must be unique), the path (containing the name of the worker notebook to be executed), and the args, or arguments. The arguments are parameters that you will pass to the worker notebook.
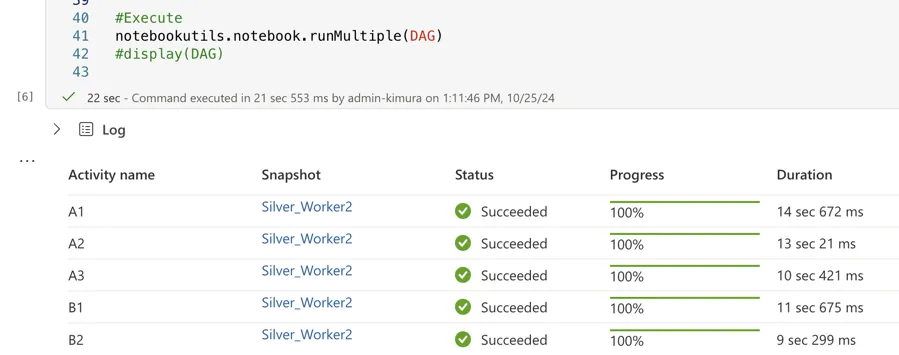
Now when we comment out the display on line 42 and uncomment the runMultiple() on line 41, we can actually execute the Silver Worker notebook in a parallel fashion:
Conclusion of Notebook Orchestration
Hopefully you have an understanding now of how we can setup notebooks in an orchestration function to help us run the lakehouse processes in an efficient manner. Using methods such as notebookutils runMultiple() make sure that we can execute many notebooks at the same time, enabling us to decrease ELT loadtimes and increase efficiency.
1 thought on “Notebook Orchestration in Microsoft Fabric”